Can't believe it's been over a year since I posted anything...nevermind, I can, cause most of 2022 and 2023 sucked. Amid a plethora of life crises, I found out in September that my comps were expiring in December, which meant it was do or die for my PhD. That and all the other terrible things that happened made these the worst few years of my life. But this isn't a life blog; I'll spare you the depressing details, so fun things only:
PhD
First, and finally, after over 7 years as a PhD student and over 10 as a grad student, I'm a Dr. Since I work with launch vehicles, do related research, and am a thermal-fluid subject matter expert, I guess I'm now officially a rocket scientist? I'm so glad it's over, feels surreal, or maybe that's just shellshock+severe burnout+trippy-exhaustion. I'm not sure I'd ever recommend getting a PhD for an aerospace engineer,
except maybe if you want to do controls or teach, but I definitely
don't recommend trying to get one while working full time. Once you start making real money, motivation and time plummets...there's nothing quite like being on grad-slave wages to motivate finishing. I've heard working while studying is not too bad with a flexible/supportive work place, an excellent advisor/department, and a
straightforward project. NASA is a fantastic place to work and, compared to most companies, very understanding of life problems and supportive of higher education. My research had data quality issues (from one
experiment I didn't design or run) and was anything but
straightforward. That + life :( + real job $= zapped motivation to work on it = 7 year PhD. Don't do what I did, just don't. I'm glad it's over.
The projects that were part of the PhD were pretty cool, though, both related to microgravity propellant slosh dynamics. I got to ride in a Zero-G plane, which was the coolest thing I've ever done and funnest experience I've ever had.
 |
Floating upside down
|
About 1/3 of the plane puked, but I don't get motion sickness, so it was a blast for me. If you ever get the chance to go on a zero-g plane, do it. I'm still writing a bunch of papers from this research and stuff that spun off it.
Mill
I got a mini mill off marketplace for a steal.
 |
Mini mill is mini
|
Now I have a mini-mill and mini lathe (relocated), though haven't done (had the time and energy to do) much with either yet. It's sitting on the antique workbench I refurbished....oh! I learned from a car guy why the oil-based paint took forever to harden: FL humidity. You really need to use a dehumidified paint booth in FL. I'll probably make one out of a pop up tent and AC/dehumidifier next time I need to paint something.
Really, it's not a life blog...well, maybe a little
I'm jealous of people who have big home machine shops. That's been my dream since MIT, actually probably since high school, although I can't remember much of anything from back then. I know the me-from-then would be depressed to hear I'm still not quite there yet. I can now see the light at the end of the tunnel, but getting there is, and will continue to be, so much slower than I'd like. Part of the reason is this house...the garage has a low ceiling and is at the bottom of a steep driveway, there's just no good way to get a large mill or lathe in it. Also doesn't have land to build a shop. So I'm planning to move...eventually. House has a bunch of issues that have to be fixed before I can sell it, but it's not like I can afford a house with the current interest rates even after selling this one, so heck knows when that'll happen.
Also, I mentioned NASA is a great place to work, but the salaries are badly lagging industry ...That was always to true to an extent, but inflation and talent demand from all of the rocket companies has made it so much worse the past few years. I applied to blue origin and got an offer way (wayyy) over what I make now, but it came down to a quality of life (more hours, no work from home, less PTO, etc) vs. money thing. I ultimately stayed at NASA. I mentioned my life was sucking...not going to try to convey that here, but most of that wasn't money driven, so I think choosing QoL over money was the right choice, despite a lack of funds being one of the reasons I don't have a nice shop.
I know I said this wasn't a life blog, but I want to say this: life is messy. There are so many posts, articles, blogs, vlogs, etc showing people having everything you might want and living perfect lives...all of it is garbage. They only show you what they want you to see. Unless you're rich, real life isn't like that, so don't feel bad when you see that crap. AI is just making that worse because now pretty much everything on the internet can be faked: pictures, videos, and even whole blogs. There is so much click-bait like "I built this [insert amazing thing] in 1 day!"...bullshit. Them lying like that to generate ad revenue bugs the shit out of me if I let it. I try to be open/honest about how much time and effort the projects I document in this blog take, and I mention everything that inevitably goes wrong. I also don't, and will never, monetize this blog. Ignore all the BS, do your own thing, go at your own pace, and try to have fun when life isn't sucking. I know I'll probably be 40 before I get the shop I want, about 20 years later than I wanted, but I'll get there.
Small Parts Organization
While I didn't have time to do much else related to the shop, I did have time to finally organize all of my screws and small parts. You can actually see some of the organizers I started to accumulate back in late 2021 in a picture in
this post, but I didn't start organizing in earnest until this year. The organizers are the
Hypertough ones from Walmart, which are the same as the HDX ones from Home Depot except the HDX ones have orange latches and inserts instead of red. They come in 2 packs, used to be $10, then it was $12. Ended up needing over 30 of them. I designed bin
inserts for the organizers, which actually cost more in filament than just buying more organizers, though they do save space and are convenient. I designed stackable cabinets to hold them.
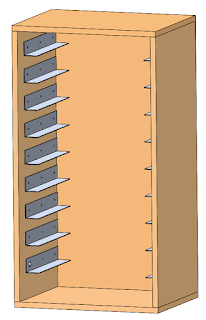 |
Small parts organizer cabinet
|
There are a bunch of neat cabinet designs out there for these and other brand organizers. The organizers I'm using had the lowest $/volume ratio I could find, and I think this cabinet will take less time to build than one based on
dados. The panels are 3/4 plywood, glued and pocket-hole-screwed. The rails are 1.5x1.5x1/16" aluminum angle, which I can source locally from a place in orlando for cheap, and they may even cut them for me, though I could cut them with my miter saw or chop saw if I really had to. No need for wheels, part of the point of the organizers is that I can pull out the one I need and take it to wherever I'm working. I haven't built the cabinets yet because time and money, and a (functional) tablesaw would be nicer than a circular saw for cutting the panels. The organizers are just stacked at the moment. I also organized medium-sized parts, like arduinos, in storage bins:
 |
| Organized |
Oh, and as shown above, I moved the printers out of the garage into a spare bedroom-turned-hobby-room.
Rocket Garden
I 3D printed a rocket garden for my desk at work.
 |
| Rockets! |
All documents are digital now, so I decided to fill up the drab cubical real estate with these. Kind of an old pic, there are more now, and along with a 1/30th scale Apollo lander with astronauts and a rover off to the right. I'm working on a mercury-redstone and the JWST now. I found all of these files for free on the internet, though I occasionally fix things I don't like about them.
Wanhao i3
My ancient shitty, yet super upgraded, wanhao i3 just passed the 25km of filament printed mark! It works juuusssssttttttt
well enough to kill my motivation to finish CubeXY. That's also why I
haven't bought a new printer, cause that'll just kill my motivation
more. Instead, I spend more money on the i3 because that makes sense (/s). I replaced the glass bed+PEI sheet with a magnetic build plate, which is night-and-day easier to use and was worth every penny.
 |
New build plate
|
You can see the knob from a new Y-axis belt tensioner in the above pic, too. The old printed support structure crumbled, so I switch it to back-braced. The braces are now out of the way, though they are not quite as stiff.
 |
New braces
|
I printed a bunch of random things over the past year, like this
mechanical dragonfly:
For the wings, I printed one layer of clear PETG on a textured build plate, then used atomic filament bronze PETG for the rest. I think they came out decently realistic. I think the oof stones might be my favorite:
 |
Printed with Atomic Filament Marble PETG
|
Future plans:
Table saw: Come December, it'll be the 2 year anniversary of having a disassembled 113 table saw in my garage. I bought a second one recently for spare parts and it has a much nicer fence than the original. I should be able to make one nice saw from all that, and sell the left overs. I will finish it. All the pics and the blog entries on this have turned out to be super helpful since I don't remember what goes where.
Workbench: 3-year anniversary, and I don't have all of the tools that were going to go in this anymore, so it needs some re-design... 😅 I'll definitely finish this. Need a working table saw first.
CubeXY 3D printer: over 4 years (RIP). I still have all of the parts, just never got around to assembling it. But I will finish it, and it might will be awesome.
H1 rocket engine turbine display case: Now that I finally have a mill, I can cut the parts for a stand for this. Need to de-rust it first.
Homelab: I have access to compute clusters at work, so I don't have plans to build a new homelab cluster. I have (very) slowly been accumulating parts to build a dual AMD EPYC machine, which, if my calculations were correct all those years ago, it should be nearly as fast as my entire cluster was. I still have the old head node, not exactly sure what I'm going to do with it yet, maybe turn it in to a NAS since it has a bunch of drive bays. I want to set up some self-hosted services.
That's all for now.






















































{kind=link}